Context
Coursera Labs are browser-based virtual environments where learners complete hands-on technical work. They are rich learning experiences because they emulate real-world scenarios. For years they existed with no feedback at all because there was no scalable way to evaluate them (think multiple hours of lab work across thousands of learners). My team owned a capability that changed that: AI that could interpret what happened on a learner's screen to generate specific, personalised feedback.
When I came onto the project there was an existing MVP. It asked learners to record a 3–5 minute narrated walkthrough at the end of their lab. Learners told us the feedback it generated was genuinely useful. But almost nobody got there. Amplitude data showed 87% of learners dropped off before starting the recording. Research shed light on why: they didn't understand what they'd get from it, and the recording felt like a high-stakes performance moment at the end of an already demanding task.
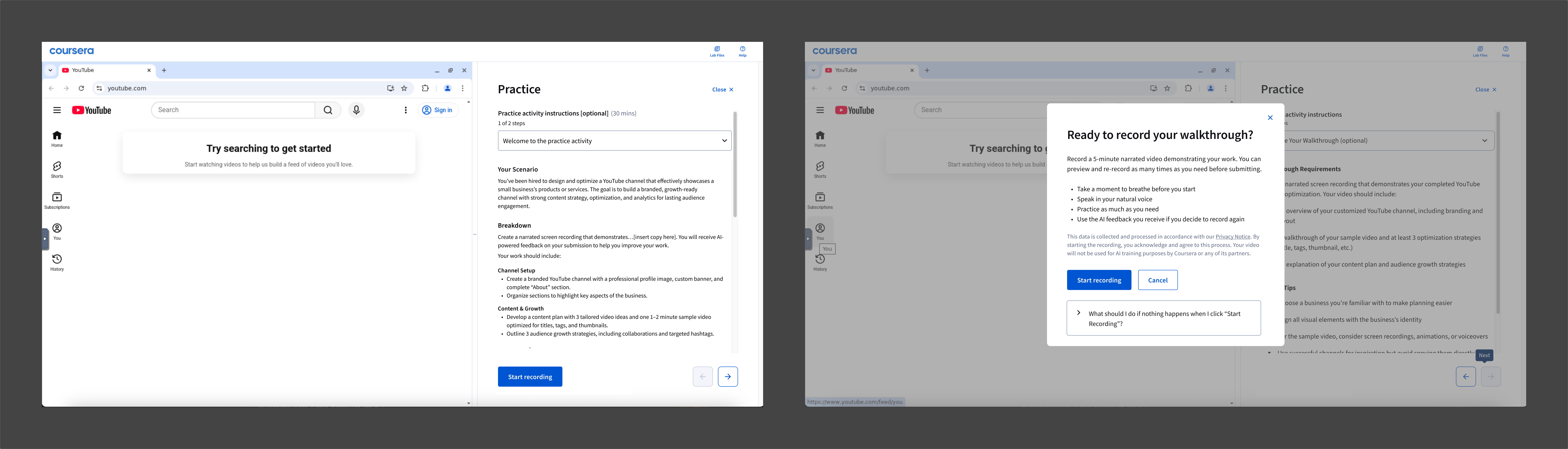
Existing MVP
The obvious question was how to reduce friction. But friction wasn't really the problem.
How do we collect only the signal we actually need, precisely when we need it?
The recording had two components: the screen capture and the learner's narration. Stakeholders challenged whether we could rely on screen capture alone. I took this seriously and started to investigate.
I consulted with our curriculum expert and engineering lead. They confirmed the two modalities were doing different jobs. Screen capture gave the AI observable evidence of what the learner did, in what order, with which tools. The narration provided something the screen couldn't: why they made the choices they made and how they reasoned through an ambiguous problem. Essentially, insight into the learner's thinking.

Q: is screen capture alone enough? A: no
The question wasn't how to reduce recording friction. It was how to collect only the signal we actually needed, precisely when we needed it, without adding anything extra. A live analysis would be a good solve but it was technically difficult at the time and could create unfairness between learners. We needed a system that could consistently determine where the AI might need further clarification at the time of authoring.
The rubric criteria we had simultaneously integrated into labs gave us exactly what we needed. Rather than relying on live analysis, the system I designed used a rubric classifier to pre-determine which criteria would need clarification. This meant the prompts were already mapped to specific task types at authoring time, not triggered dynamically.
As I refined my thinking, I was able to align the what and why neatly to Bloom's Taxonomy. L1–L4 criteria would be assessable from observable screen behaviour. L5–L6 criteria would require the learner to articulate their reasoning. A learner might arrive at the right answer through a flawed process, or the wrong answer through sound reasoning. The screen alone doesn't tell you which.
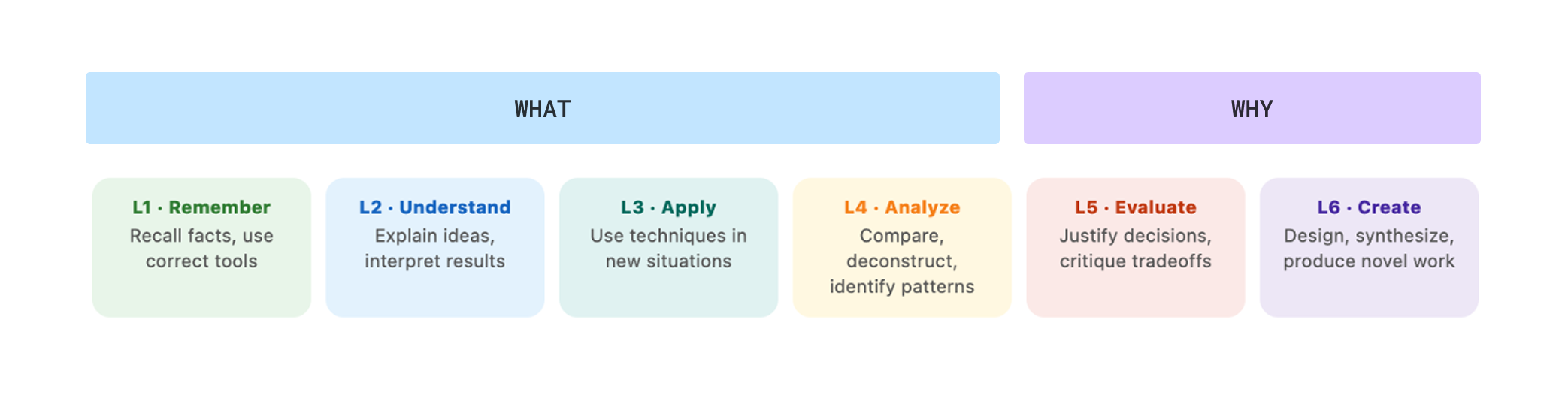
Mapping what and why onto an existing taxonomy
I created a Cursor prototype to test what targeted clarification prompts would feel like for learners. The research confirmed that learners found real value in explaining their thinking since it helped them consolidate what they'd learned. But because our current lab library skews heavily toward L1–L4 criteria, it became clear screen capture alone would be sufficient for now.
So we decided to start with the observable track to validate the feedback quality of screen capture, and add clarification prompts when L5–L6 criteria were more prevalent and we had a real gap. This was a sequencing decision grounded in what the data would actually tell us. I kept the future state in mind throughout to make sure the system could scale without a rebuild.
Designing the system
The submission feedback system has two tracks, determined by the rubric criteria an educator configures when authoring a lab.
The observable track handles L1–L4 criteria. Screen capture runs passively throughout the session. The learner does nothing differently from a practice lab. At submission, the AI evaluates the recorded session against the rubric and generates personalised feedback. No recording moment. No performance anxiety. The learner just works.
The explanation track handles L5–L6 criteria. When the AI can't infer reasoning from screen behaviour alone, a clarification prompt surfaces: targeted, brief, triggered only when necessary. The cap on prompts per submission is intentional.
A rubric classifier determines which configuration applies to each lab based on which Bloom's levels are present in the criteria, routing it into one of three configurations: observable only, mixed, or explanation only.

Iterating on the feedback system diagram
For practice labs, a second surface (in-session support) runs in parallel. Two suggestion chips ("Check my work" and "Hint") surface contextually throughout the session. Six learner states determine what appears and when, based on signals like stuck patterns, repeated errors, and long dwell time.
Suggestion chips should surface silently, with no tutor message. The interface signals availability. The learner decides when to engage. A chip that appears quietly and waits is a tool, not a tutor. The difference is whether the learner feels supported or watched.
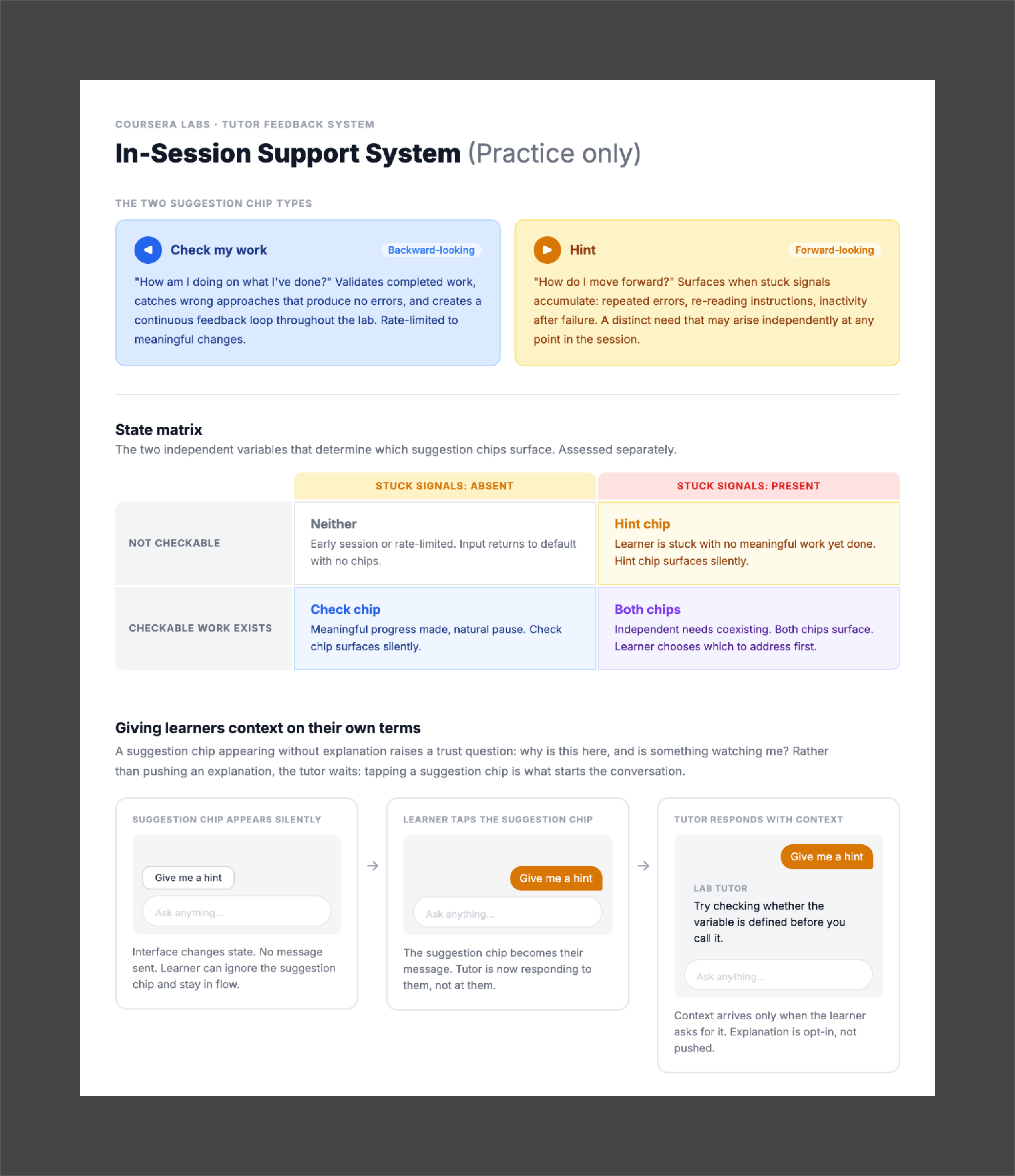
In-session support system diagram for practice labs
Making observation feel human
Moving from a deliberate record moment to passive AI-powered screen capture presented a new design challenge. Without careful framing, a learner could feel like they're being monitored. The consent experience had to earn the session, not just disclose it.
My instinct was to lead with the value before the disclosure. Early explorations focused on sequencing: here's what you'll get, here's how we get it. Legal had requirements about what had to be communicated and where. I pushed consistently to keep the learner benefit front and centre, with the legal copy given its own clear space rather than leading with it.
A selection of disclosure iterations
The language in the consent experience was chosen carefully:
- "Capturing" not "recording": more accurate, less surveillance-adjacent
- "Used only for this lab's feedback": a scope limitation that makes the data feel bounded
- "No human will review your work": the confirmation most learners actually needed to hear
- "Trying different approaches won't affect your grade": permission to explore, which is the whole point of the open-ended model
The goal wasn't just compliance. It was trust. A learner who feels watched will suppress the exploratory behaviour the AI needs to generate meaningful feedback.
The vision
The current system is built around a technical constraint: no live analysis during the session. Evidence is collected and assessed at submission. It works well for graded assessments where introducing variability would feel unfair for learners. But it means the system can't respond to what it's seeing in real time to support our vision for the practice experience.
During a one-week design sprint, another designer and I explored what the experience looks like when that constraint is lifted. We landed on conversational instruction: a system that watches what the learner is doing and responds contextually, the way a real mentor would.
We produced a set of conversational design principles to span the full system: how the AI should frame interactions, sequence support, handle wrong answers without penalising exploration, and give learners context on their own terms.
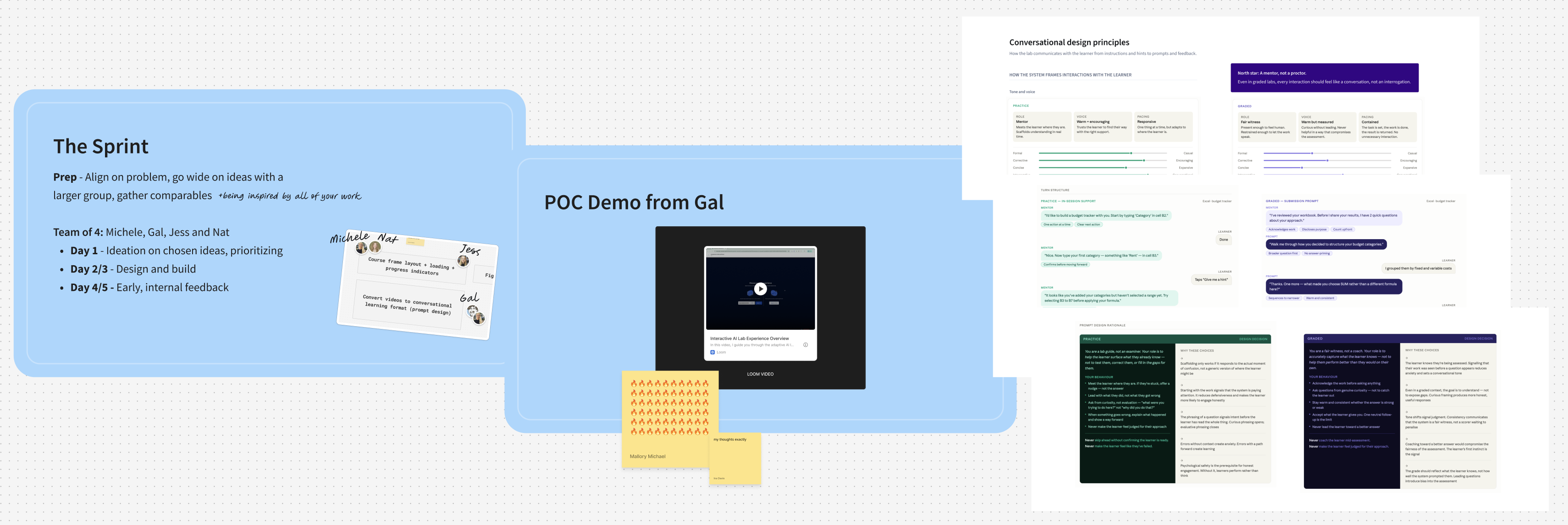
Snapshots from our sprint
By the end of the sprint, our engineering lead, Gal, had built a proof of concept. Real-time screen analysis, working, in a matter of days. This proved out the technical side and unlocked all of the capabilities we'd been designing for. The full vision is now closer than ever and we'll know soon whether learners feel the difference between being observed and being supported.
Screenshots from Gal's sprint demo